The VuFind Browse Handler

I developed the first version of VuFind's browse handler while working at the National Library of Australia. The source code was released as open source and contributed to the VuFind project.
This article gives a brief summary of what browse is all about, and shows how the VuFind implementation of browse hangs together.
Overview
Alphabetic browse provides a hierarchical way of navigating library collections. Here's what you can do with it:
You can view a sorted list of values (known as "headings") for some particular attribute. For example, a sorted list of all authors in a collection, or all subjects, or all titles.
You can jump to any point in a sorted list of headings by providing the first few letters of your starting point. For example, searching for "Tri" might jump you to the heading for "Triggs, Mark" (if I'd authored any books...). This lets you navigate through the sorted list—much like a phone book as in days of yore!
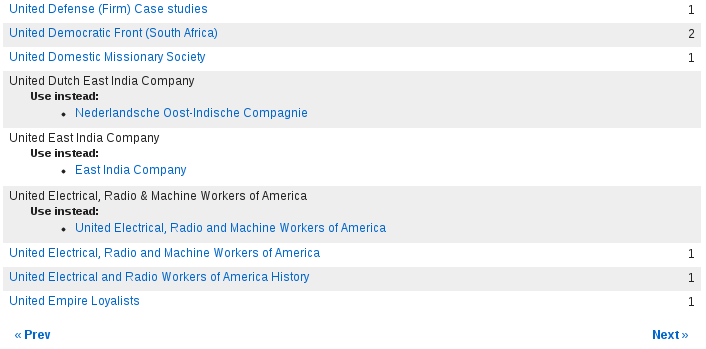
For each heading displayed, you can see several pieces of information:
The number of records relating to that heading. For example, the number of books an author has written, or the number of books within a certain subject category.
A list of "Use Instead" references. Sometimes one heading will be superseded by another: an author might change their name, or a subject category might be renamed to better reflect modern usage (such as renaming "cookery" to "cooking"). In these cases, a "Use Instead" will direct you to the preferred form of a heading.
A list of "See Also" references. These direct you to other headings that relate to the current one in some way.
A list of notes. These are snippets of text that have been added by cataloguers to give more information about a particular heading.
If you click on a heading, you will be taken to a list of all records within that heading.
Put it all together, and you get something like this (taken from Villanova's VuFind instance):
The major pieces
Alphabetic browse is made possible by several components working together. These are:
The VuFind bibliographic index. This contains the records that power VuFind's search function. The browse handler makes use of this index to work out how many records are within each heading.
The VuFind authority index. These indexes contain authority records, which provide the "Use Instead", "See Also" and notes information described in the previous section.
The browse indexes. These are SQLite databases (one for each browse type) that store the sorted list of headings. Headings are stored in a single table with two columns: one for the text of the heading, and one for the heading's "sort key", which determines its position in the sorted list.
The browse indexing program. This interrogates the bibliographic and authority indexes to build the list of headings. From these, it creates the set of browse indexes described above.
The Solr browse handler. This is a custom Solr request handler that pulls everything together:
It takes the attribute to browse by (e.g. author, subject, title), page number, and an optional search query
It uses the appropriate browse index to build a sorted list of headings using the user's query (if any) as a starting point
It works out which results are required to fill the page that the user asked for
It searches the VuFind bibliographic index to tally up the record count for each heading
It searches the VuFind authority index to pull in any references or notes
It sends the result back to be displayed
The browse handler also tracks changes to the browse indexes, automatically making use of updated versions as they become available.
The implementation
VuFind's browse code is open source. The authoritative version of the code can be found here: https://github.com/vufind-org/vufind-browse-handler.
Browse indexing
Browse indexing is the process of extracting terms from VuFind's bibliographic and authority indexes, and producing a sorted list of headings. The resulting list is stored in SQLite for convenient access.
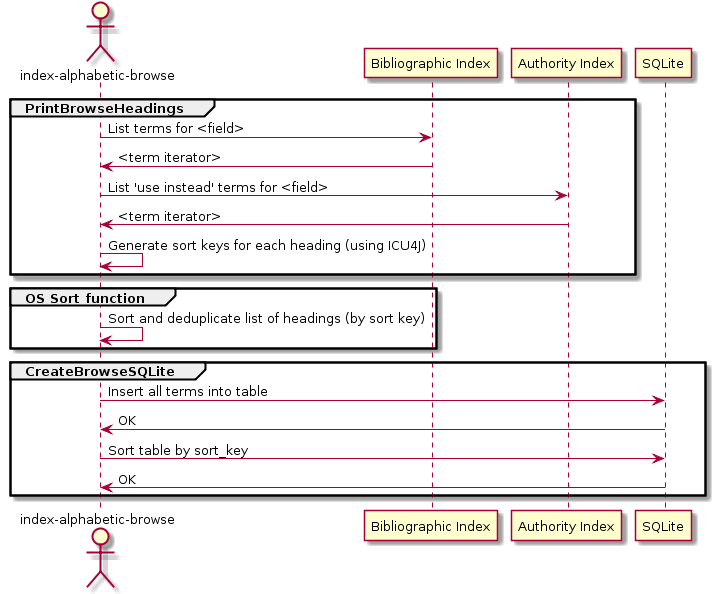
Indexing is divided into three major steps:
PrintBrowseHeadings extracts relevant terms from the bibliographic and authority Lucene indexes, generates a sort key for each heading, and writes the headings to a file.
The Operating System's Sort Command orders the headings by sort key and removes any duplicates.
CreateBrowseSQLite reads the list of deduplicated headings and produces a sorted SQLite database of headings.
The sort key is a byte sequence produced by ICU4J. This key determines the ordering of the headings, taking into account punctuation and multi-byte characters.
The indexing process is summarised in the following diagram:
Browse handling
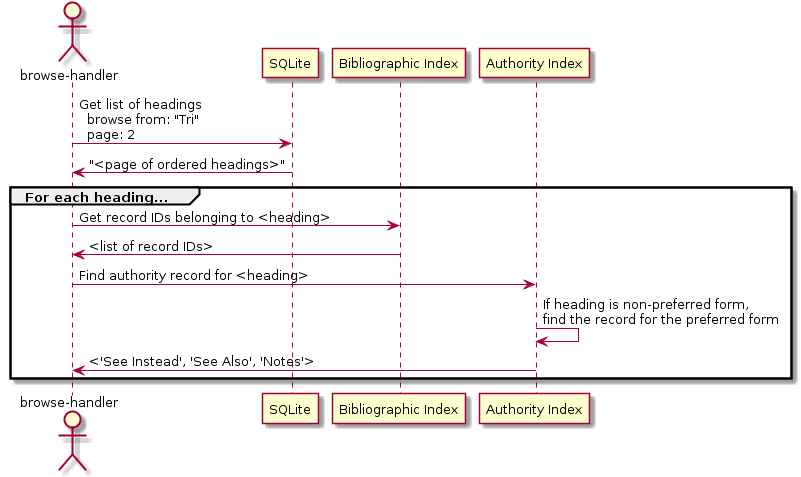
The browse handler is a Solr request handler that combines the results from SQLite, the bibliographic index, and the authority index. It handles each browse request by:
Asking SQLite for the requested page of headings (taking into account the browse starting point and requested page number).
Cross-referencing each heading in the bibliographic index to find the list of record IDs that match.
Cross-referencing each heading in the authority index to incorporate "See Also", "Use Instead" references and notes.
Frequently asked questions
Why do we need a database and Solr?
In principle you could build a browse straight off your Solr indexes by using the Lucene API directly—by writing a Solr query component that opened the bibliographic index and used a Lucene TermEnum to seek to the right term of the index being browsed.
The sticking point for this is sorting: Lucene will give you a single field in sorted order, but for browse we want to sort by one field (with collation, etc.) but display another. There might be ways of getting around this (like prefixing each term with its sort key and stripping it off at runtime), but it's hard to beat the simplicity of SQL for this (particularly once you throw forwards/backwards pagination into the mix).
Why SQLite and not something else?
Mainly because it was convenient when I first wrote the code. It works on multiple platforms, is OS-cache-friendly, and is simple to update (just build a new database and throw away the old one).
Can I change the way headings are sorted?
Sure. You can write your own "Normaliser", which can produce sort keys using whatever scheme you desired. I've prepared an example here that you could start with: https://github.com/vufind-org/vufind-browse-custom-normaliser.
When I try a browse it always takes me to the top of the list!
In April of 2012 I switched the browse code from using a home-grown sort key generator to using ICU4J. This had the benefit of allowing locale-specific sorting rules and proper UTF-8 handling, but changed the sort keys in a way that wasn't backwards compatible.
People occasionally report their browses jumping them to the top of the list of headings. This is a good sign that your browse indexes were built using a different version of the code to what you're now running.
To troubleshoot:
Check that your versions of the following files match the ones that shipped with your version of VuFind:
vufind/solr/lib/browse-handler.jarvufind/import/browse-indexing.jar
Remove your existing browse indexes by deleting:
vufind/solr/alphabetical_browse
Then rebuild the browse indexes by running
index-alphabetic-browse.sh(orindex-alphabetic-browse.batif running under Windows)
Links
Questions? Hassle me at mark@teaspoon-consulting.com.