Migrating to ArchivesSpace

I have recently worked with several institutions who are in the process of migrating their collections to ArchivesSpace. This guide is primarily intended for people who are migrating to ArchivesSpace from the Archivists' Toolkit, but much of the advice is generally applicable. I'm hoping to add more tips and tricks over time, so please don't hesitate to drop me a line and share your experiences!
System migrations are always daunting—usually offering the unique opportunity to feel both clueless as you stumble your way around a new system and guilty as you come face-to-face with the quality of the data in your existing system. Are you the world's worst archivist? Maybe.
But you're not alone! And while learning curves and data issues are unavoidable, you can at least have some idea of the general direction you're heading in. This article aims to provide this direction: giving an overview of the steps involved in getting your records out of the Archivists' Toolkit and into ArchivesSpace.
Planning your migration
Although this guide is structured as a neat sequence of steps for performing a migration, reality is rarely so kind. Real migrations are generally iterative: you'll run through the migration steps, see what fails, tweak your data (or the migration process), then repeat. Remember that system migrations are really data cleanup exercises in disguise, so give yourself plenty of time to address the problems that will inevitably occur.
Since you'll be running through the migration steps multiple times, it's a good idea to try to reduce the friction of this process as much as possible. For example, if you have some technical savvy (or if you're interested in acquiring some) you can save yourself a lot of time by testing the migration process on a machine that you control. ArchivesSpace is easy to install, and being able to clear your database and re-run the migration process yourself is a good deal better than waiting a day or two for your overworked IT department to respond.
Before you start
Take a backup of your Archivists' Toolkit database! Although the migration process is non-destructive (i.e. records are copied into ArchivesSpace, not moved), this is a great time to make sure you have a copy of your database as it was before the migration. Six months down the line, you might be pleased to have a snapshot that you can refer back to.
Configuring ArchivesSpace for migration
To get started, you will need an installation of ArchivesSpace. Download the latest release from https://www.archivesspace.org/ and follow the installation instructions at https://github.com/archivesspace/archivesspace. You will want to configure ArchivesSpace to use a MySQL database, so be sure to follow the instructions in the "Running ArchivesSpace against MySQL" section.
There are a couple of configuration settings we can apply to
ArchivesSpace to help us on our way. To apply these settings, open
the config/config.rb file (within your ArchivesSpace directory) and
add the following lines to the bottom:
AppConfig[:enable_solr] = false
AppConfig[:enable_indexer] = false
This will disable the indexer while the migration is running. While not strictly necessary, these can help to reduce the time required for migration—we'll run the migration, then index everything in one shot at the end.
Save that file and restart your ArchivesSpace instance.
Running the Archivists' Toolkit Migrator
You will need to download the latest version of the Archivists' Toolkit plugin from the distribution page:
https://github.com/archivesspace/at-migration/releases
Download the scriptAT.zip file and place that in the plugins
directory of your Archivists' Toolkit installation. Now, start the
Archivists' Toolkit and log in as usual. From the menu bar at the
top, select:
- Tools
- Script Runtime v1.0
- Archives Space Data Migrator
This will pop up a new window that looks like this:
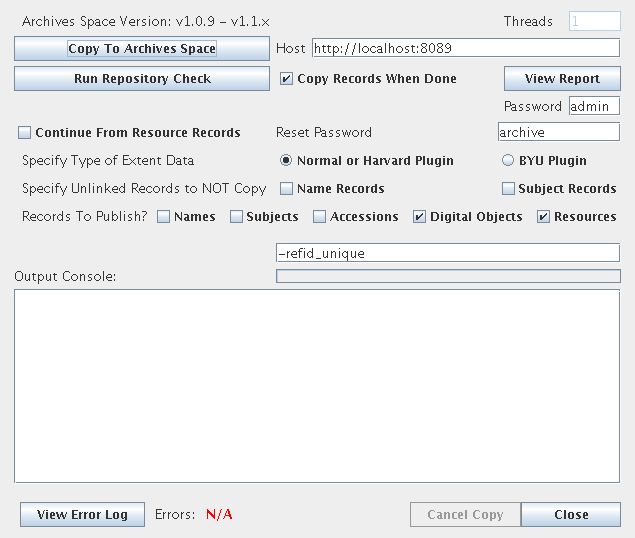
Unless you have special requirements, you will just need to fill out the "Host" field to point to the backend of your ArchivesSpace system. If you normally access your ArchivesSpace installation using http://archivesspace.example.com:8080/, your backend URL will likely be http://archivesspace.example.com:8089/.
Once you've filled out this field, you're ready to run the migration. Click the "Copy To Archives Space" button at the top-left of the window and watch the "Output Console" for any errors. Try to resist clicking the "Cancel" button while the migration is running (sometimes that's harder than it sounds...)
If there are errors in your data that stop ArchivesSpace from accepting the records, they will be logged to the "Output Console" of the migrator tool. Sometimes the easiest course of action is to drop and recreate your ArchivesSpace database, fix the record(s) in the Archivists' Toolkit and then run the migration again. That's fine: as noted previously, migrations are an iterative process, and no points are awarded for doing it all in one shot.
Indexing your data
Once the migration has completed successfully, you can restart Solr
and the ArchivesSpace indexer to make your data searchable. To do
this, shut down ArchivesSpace, edit your config/config.rb file and
remove the lines:
AppConfig[:enable_solr] = false
AppConfig[:enable_indexer] = false
This will cause the indexing system to run when ArchivesSpace is next started.
Advanced stuff
If you have a lot of data (say, millions of records), you might also want to take the opportunity to increase the default settings to make the indexing finish more quickly. For example, if you are running ArchivesSpace on a powerful server with plenty of memory (say, 8 cores and 2GB of memory), you could add settings like these:
# Allow 100 connections to MySQL
AppConfig[:db_max_connections] = 100
# Run 6 indexer threads at a time...
AppConfig[:indexer_thread_count] = 6
# ... and have each indexer thread work in batches of 50 records
AppConfig[:indexer_records_per_thread] = 50
In this case, you would also want to increase the amount of memory
allocated to the ArchivesSpace application. You can do that by
editing your archivesspace.sh (or archivesspace.bat) file, and
replacing all occurrences of -Xmx1024m with -Xmx2048m (to give the
application 2GB of memory)
Starting it up
You are now ready to start ArchivesSpace and let it index your data. Start ArchivesSpace as normal and watch its log file; you should see lots of lines whizzing past like:
Indexed 73300 of 133112 accession records in repository MYREPO
Indexed 73350 of 133112 accession records in repository MYREPO
Indexed 73400 of 133112 accession records in repository MYREPO
Indexing can take a while to finish the first time it runs. As a rough estimate, an ArchivesSpace installation with 2 million records might take around 2 hours to fully index. You should see your data begin to appear as the indexing runs, and there's no harm in getting in and poking around while that happens.
Post-migration tasks
With all of that, you should have a functional ArchivesSpace system. Congratulations! Here's a laundry list of other things to make sure you've covered off:
Make sure you're taking backups of your ArchivesSpace database and your Solr indexes. See the "Backup and recovery" section of the documentation at https://github.com/archivesspace/archivesspace for helpful tips.
Consider posting to the ArchivesSpace mailing list and/or Twitter to brag about your achievement.
Other resources
The ArchivesSpace mailing list is frequented by several institutions who have been through the migration process. Join us for group therapy!
The ArchivesSpace site provides documentation for migrations from various systems, which you can find at https://archivesspace.org/using-archivesspace/migration-tools-and-data-mapping.
Kitchen sink
You really don't need to read these, but here are some random thought fragments that don't fit anywhere just yet.
If you need to modify the Archivists' Toolkit Migrator source code, here is how you can build it from the command-line under Linux/OS X (without having to use an IDE):
mkdir -p build javac -cp 'lib/*' -d build -sourcepath src $(find src -name "*.java") jar cvf scriptAT.zip -C build . plugin.xml $(find src -name "*.bsh")You can also run the Archivists' Toolkit migrator from the command-line (without having to start the Archivists' Toolkit too). To do that, create a file called
dbcopy.propertiesin the same directory you build the migrator in:useTracer=false tracerDatabase=2 clientThreads=1 checkRepositoryMismatch=false continueFromResources=false resetPassword=archive simulateRESTCalls=false ignoreUnlinkedNames=false ignoreUnlinkedSubjects=false publishNames=true publishSubjects=true publishAccessions=true publishDigitalObjects=true publishResources=true copyOnlyResources=false checkISODates=false databaseType=MySQL atUrl=jdbc:mysql://localhost:3306/mydb atUsername=mydb atPassword=mydb aspaceHost=http://localhost:8089 aspaceAdmin=admin aspacePassword=adminThen run the migration with:
mkdir -p logs nohup java -Xmx1024m -cp "scriptAT.zip:lib/*" org.archiviststoolkit.plugin.dbCopyCLI &> logs/run.log &If you're indexing lots of records, you might want to disable the Solr backups while the initial index runs. You can do that by editing
config/config.rband adding a line like:AppConfig[:solr_backup_schedule] = nilDon't forget to remove it once you're done, or you won't have any Solr backups!